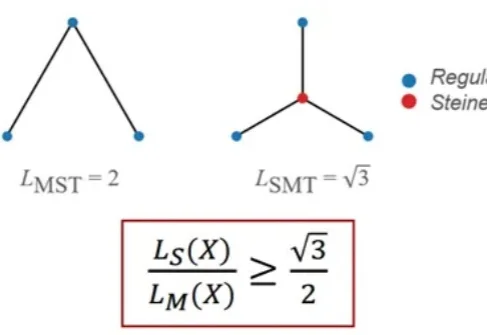
LLM助力突破尘封60年数学猜想!北大王立威团队大幅刷新斯坦纳比下界
LLM助力突破尘封60年数学猜想!北大王立威团队大幅刷新斯坦纳比下界近期,LLM 已经在 IMO 上取得了很好的成绩,在一些研究级数学上(如短程证明、组合构造)也有所进展。但如果真正让 LLM 去处理提出数十年的数学猜想,结果会是如何?
来自主题: AI技术研报
5610 点击 2026-05-18 15:29
 搜索
搜索
近期,LLM 已经在 IMO 上取得了很好的成绩,在一些研究级数学上(如短程证明、组合构造)也有所进展。但如果真正让 LLM 去处理提出数十年的数学猜想,结果会是如何?
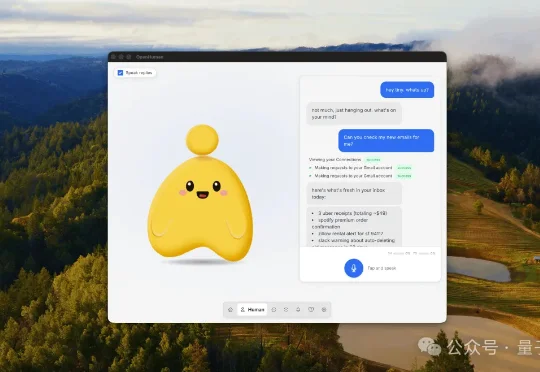
虾在前,马当道,居然还有新物种能在Agent赛道突出重围。OpenHuman连续霸榜GitHub Trending第一,狂揽9k+ Star,一天就涨千星。和虾马不一样,Human不用你花心思养,还能反过来主动了解你。

为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。
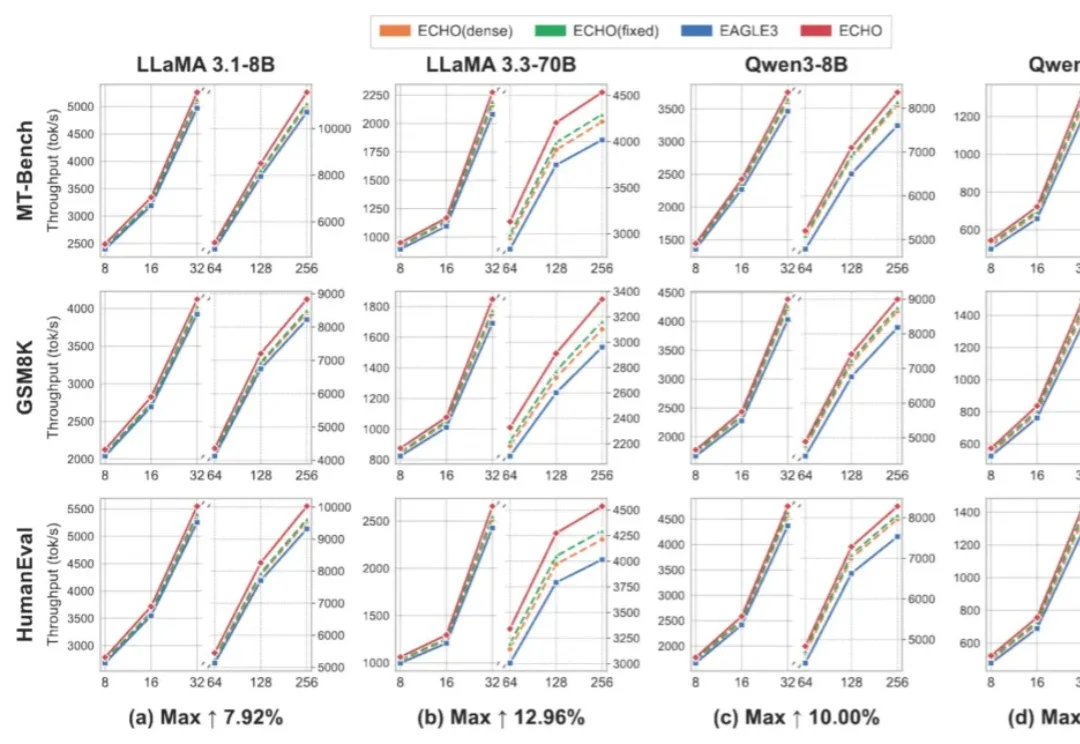
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。

“LLM 就是一条死路。”
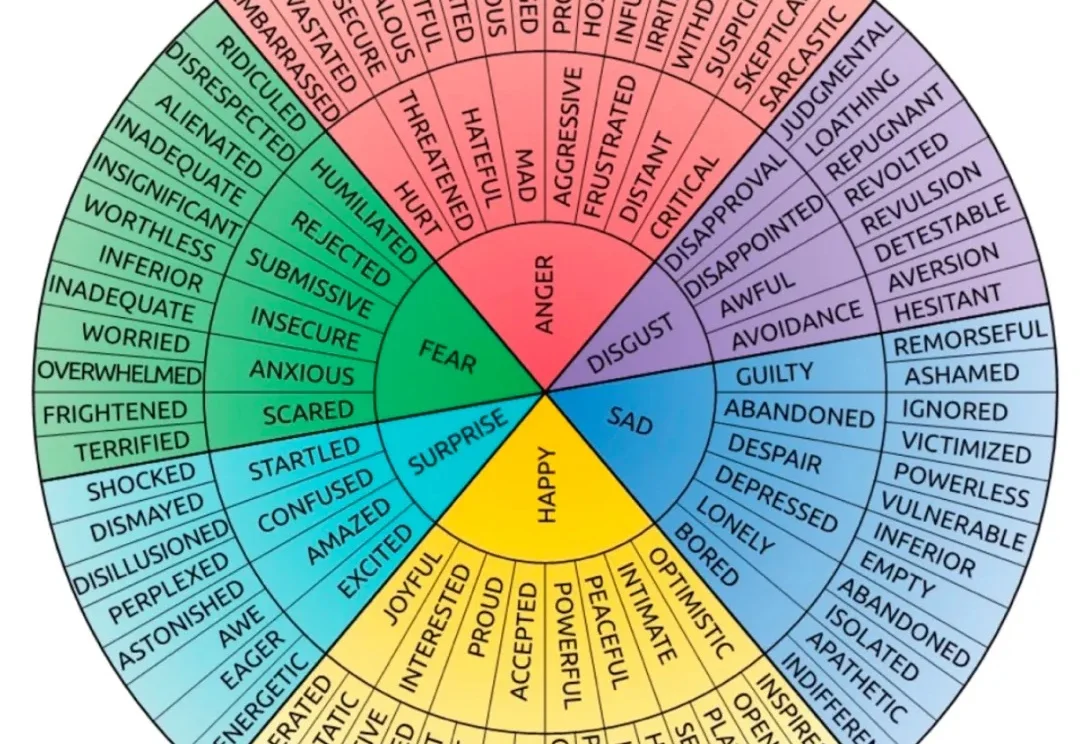
随着语音、视频、多模态能力不断融入大语言模型(LLM),人与 AI 的交互正在越来越接近自然对话。今天的 LLM 不再只是回答问题的工具,也越来越多地出现在教育、客服、陪伴、心理健康等高度依赖情绪理解的场景中。
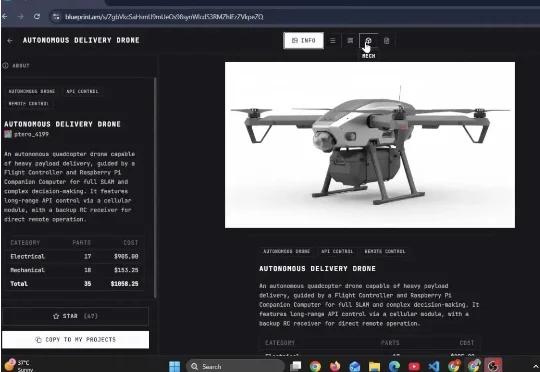
大家好,最近有人刚刚为电子产品开发了一个 Claude Code 工具。 它叫做 Blueprint。输入你想要构建的内容,它就会为你的 Arduino 或树莓派项目生成接线图、物料清单和分步组装指南。能不能自己搭建一个呢?

刚刚,Anthropic 发布论文《Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations》,试图用一套 自然语言自动编码器(Natural Language Autoencoders,下文简称 NLA), 撬开这个黑箱。

当地时间 5 月 5 日,迈阿密一家名为 Subquadratic 的公司走出隐身模式。CTO Alexander Whedon 在 X 上把首款模型 SubQ 称作“a major breakthrough in LLM intelligence”(LLM 智能领域的重大突破),
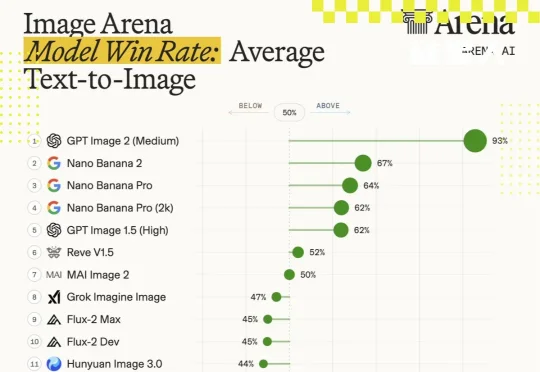
GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。